La notion de MVP est maintenant largement démocratisée pour les produits web et mobiles. Définir les parcours et fonctionnalités indispensables pour un coût maîtrisé est un exercice que pratique la majorité des Products Managers. Mais comment appliquer le même principe à un Produit Data Science ?
Un modèle naïf, mais activé
Dans sa version la plus simple, un Produit Data Science est constitué de données prises en entrée (préparation), d’un algorithme qui les combine et les transforme en données de sortie (modélisation). Cette donnée est ensuite délivrée à l’utilisateur final de telle sorte qu’il puisse en tirer de la valeur (activation).
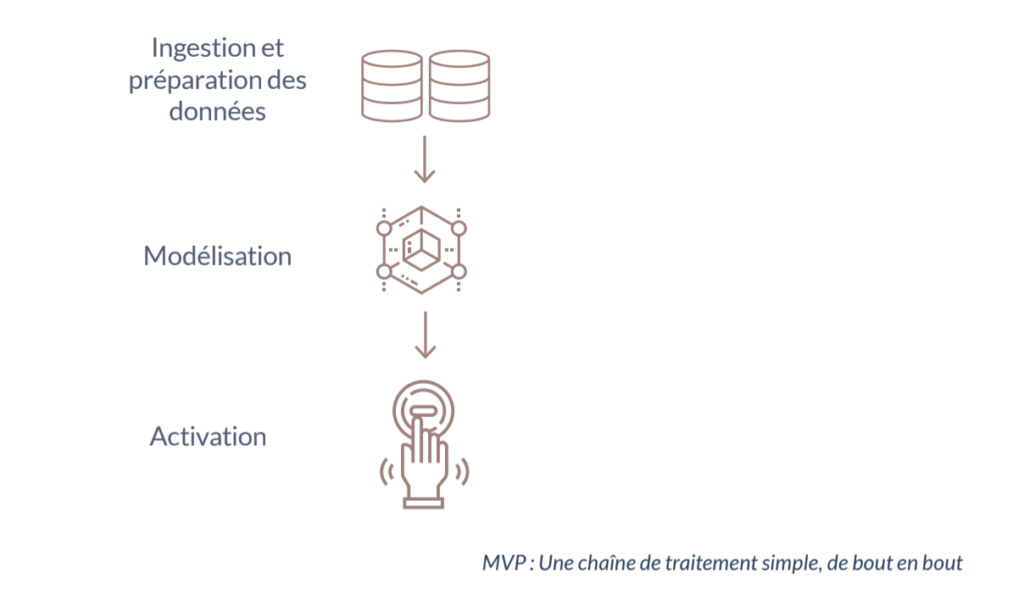
Dans le cadre d’un MVP, l’objectif sera de simplifier au maximum ces trois briques.
Ingestion et préparation de la donnée
Lorsque vous avez imaginé votre Produit Data Science, vous avez probablement vu grand. Vous imaginiez déjà le croisement de dizaines de sources de données de format et de nature différents. Dans le cadre de la réalisation de votre MVP, vous allez vous contenter de l’ingestion des sources absolument nécessaires. Les autres pourront être ajoutées au gré des améliorations ultérieures.
Modélisation
Concernant la modélisation, nous allons chercher à nous abstraire d’un modèle de Machine Learning. Des algorithmes plus complexes pourront être mis en place par la suite. Néanmoins, dans un premier temps, nous allons nous contenter d’algorithmes dits naïfs. Cela signifie qu’ils se contenteront d’appliquer des règles métier sous la forme de règles mathématiques simples ; comme des moyennes ou des briques de Machine Learning pré-implémentées.
Non seulement cette approche permet d’obtenir rapidement un modèle en production, mais elle a de plus l’avantage d’obliger l’équipe à acquérir la connaissance métier pour réaliser cet algorithme, ce qui sera fort utile pour la suite.
Activation
Il reste maintenant à délivrer le résultat de ce premier modèle à l’utilisateur final. Nous avons vu que l’interface utilisateur cible de notre produit doit être IPAP, dans le cadre d’un MVP. Cependant, nous nous concentrerons sur les aspects Intuitif et Actionnable, et nous laisserons de côté les aspects Pratique et Personnalisable.
Pour cela, mettons automatiquement à disposition les résultats à notre utilisateur sous la forme la plus simple. Cette action lui permettra de comprendre les résultats du modèle et de les actionner. Les subtilités dans les résultats et leur mise en perspective avec d’autres éléments via des visualisations complexes n’est pas à l’ordre du jour, pas plus que l’interfaçage avec les outils du quotidien. Le seul objectif ici est de permettre à l’utilisateur de tester notre produit en conditions réelles. Ainsi, il pourra nous orienter sur sa pertinence.
Tester en conditions réelles

Par définition, le MVP est imparfait. Des prédictions ou recommandations risquent d’être erronées et l’activation peut ne pas être appropriée à certaines situations.
Dans quelques rares cas, la valeur apportée par le MVP est telle que l’on peut s’en accommoder. Malheureusement, les problèmes traités par un Produit Data Science sont souvent critiques. Il est alors nécessaire de prendre quelques dispositions pour permettre de tester votre MVP en conditions réelles ; et de bénéficier de retours utilisateurs tout en limitant l’impact de ces imperfections.
Garder une activation manuelle
En vision cible, le produit sera entièrement indépendant et automatisé. Néanmoins, il peut être intéressant de garder dans un premier temps une part manuelle pour l’activation. Prenons le cas d'un outil de type chatbot dédié à de la relation client. Plutôt que de proposer directement un moteur de conversation totalement automatisé, le MVP pourrait consister à aider les membres du service client (qui continueraient à piloter les conversations eux-mêmes) en leur suggérant des réponses appropriées. On apporte ainsi de la valeur (gain de temps) ; mais on récolte aussi un retour sur la qualité de la réponse (sélectionnée ou non).
Sur un sujet aussi critique que la prédiction de défaillance de pièces d’un avion, Air France utilise un système de test ingénieux. L’outil devait prédire la défaillance potentielle d’une pièce présente en plusieurs exemplaires sur un avion ; une principale, en position critique, dont la panne empêche l’aéronef de partir, et trois autres dont la défaillance permet de décoller sous condition. Ainsi, lorsque le modèle prédisait une défaillance de l’équipement sur la position critique, celle-ci était permutée avec une autre située sur une position moins critique. De cette manière, le risque de faux positif par mauvaise prédiction était écarté (pas de pièce changée inutilement), tout en permettant d’observer le comportement de la pièce pour confirmer la défaillance (récolter des retours utilisateurs). Cela a permis de commencer à apporter de la valeur ; si la pièce déplacée en position moins critique rencontrait effectivement une défaillance, on évite l’annulation et l’avion pourra partir sous tolérance.
A/B Testing
Cette solution est utile lorsqu’il s’agit de remplacer un outil existant. Une partie des choix est réalisée par l’ancien outil et une partie par le nouveau. Dans le cas où il y a un nombre d’occurrences suffisant, on peut orienter un faible pourcentage de choix vers l’outil test. L'objectif est de garder une significativité statistique tout en limitant l’impact sur l’utilisateur.
Restreindre le périmètre
Lorsque le produit doit gérer beaucoup de situations, il est intéressant de se focaliser sur une sous-partie du problème. Prenons l’exemple d’un Produit Data Science ayant pour objectif de prédire les ventes d’une chaîne de magasins de fruits et légumes. Pour éviter de courir le risque de confier la totalité de l’approvisionnement à votre MVP, vous pouvez commencer par tester sur quelques magasins ou certains fruits spécifiques.
Trois stratégies s’offrent alors à vous :
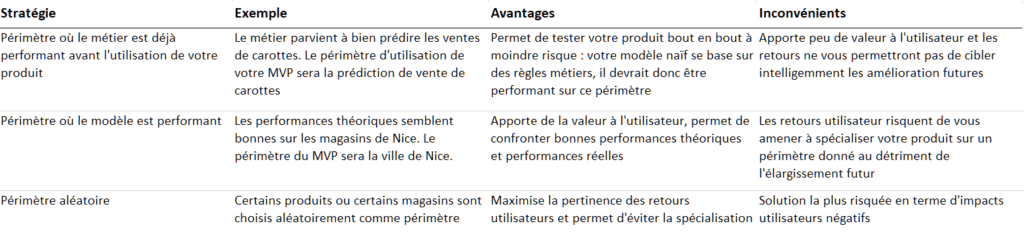
Quelle que soit la stratégie adoptée, l’enjeu sera par la suite de gérer l’élargissement progressif de votre produit au fur et à mesure que ses performances s’amélioreront.




